
The key problem of any model is overfitting and selecting a set of features that work well with a specific set of data but does not have forecasting power outside the training set. A core advancement of machine learning is solving these problems of overfitting.
Data analysis has improved greatly with the development of decision trees, non-linear analysis that looks at splits in data to determine predictions. Instead of fitting a line through a set of points and minimizing errors, the process focuses on splits across a set of variables to make successful predictions.
For an investment tree, it could be as simple as if earnings move higher by x percent, buy the stock. it is not a linear rule but focuses on action at specific splits or nodes. But how do you know that this is the right split especially if you are looking at a wide set of decisions?
The answer is to use techniques to simulate more experiments or data to test a model; sampling with replacement. This is called bagging. The random forest algorithm is an extension of bagging because it uses sampling with replacement as well as feature randomness. It is often called feature bagging. The idea is to create an uncorrelated forest of decision trees based on different features. By choosing a random set of features, a set of unique trees will be created which can then be aggregated and averaged.
The decision tree considers all possible splits to find the best splits based on some measure. The random forest looks at all possible splits but for only a limited set of features. The random forest a collection of decision tree drawn from a training set with replacement, the bootstrap or bagging approach. Added random is created through feature bagging which adds more diversity and reduces correlation across trees. The model will have to set the number of trees, the number of features for each tree and the node size. For a regression task, the set of trees are averaged. For a classification task, a majority vote can be taken. These models can then be tested on the data outside the training set.
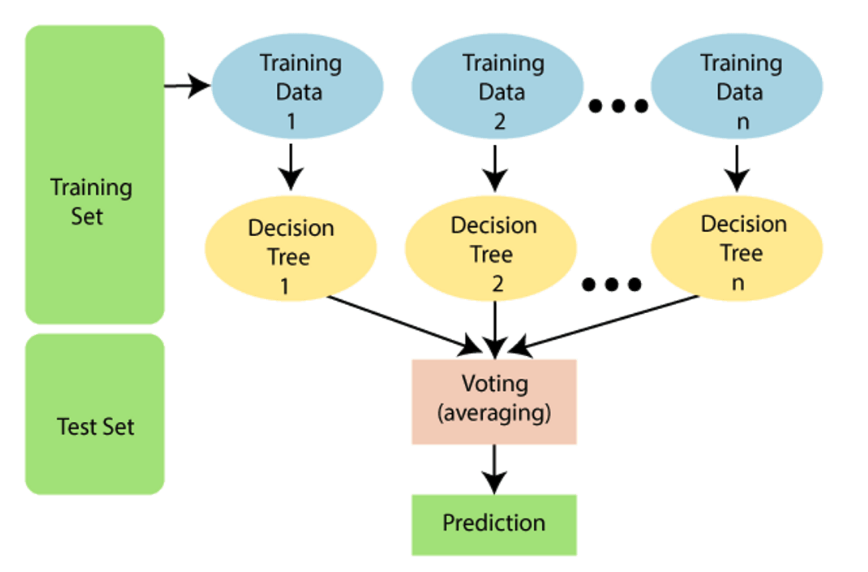
The result is a model that has less overfitting, has a high degree of flexibility, and the ability to find the key important features. The problem is that the process is time-consuming, requires a large dataset, and has a greater level of complexity over single decision tree.
No comments:
Post a Comment